




随着大数据技术的不断发展,实时数据处理的需求日益凸显,在大数据处理领域,Apache Flink因其高吞吐量和低延迟的特性而受到广泛关注,而Hadoop Distributed File System(HDFS)作为大数据存储的基石,与Flink结合可以实现高效的数据处理与存储,本文将介绍如何在12月22日这一天,利用Flink实时写入HDFS。
背景知识
Apache Flink是一个流处理框架,用于处理无界和有界数据流,它允许进行实时数据分析,并具有容错性和高可用性,而HDFS是Hadoop生态系统中的存储组件,用于存储大量的结构化或非结构化数据,当Flink与HDFS结合时,可以实现对数据的实时处理和存储。
Flink与HDFS的结合
在Flink中,我们可以使用FileSystemSink函数将数据实时写入HDFS,需要配置Flink的HDFS连接参数,包括HDFS的地址、端口、用户名等,配置完成后,就可以使用Flink的DataStream API将数据写入HDFS。
实时写入流程
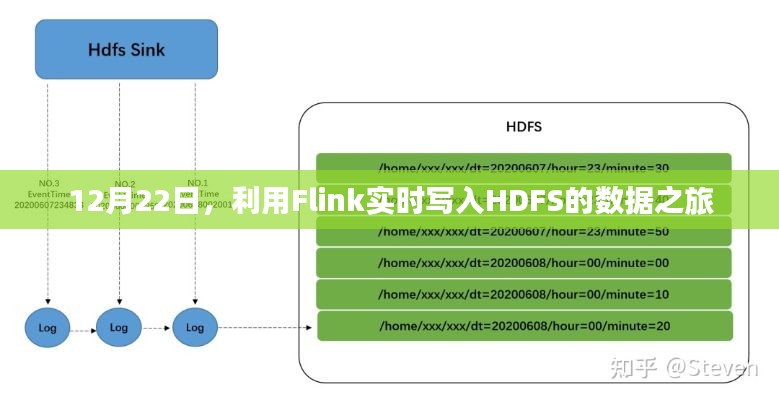
1、数据源:需要有一个数据源,可以是Kafka、RabbitMQ等消息中间件,也可以是其他实时数据源。
2、Flink处理:将数据源中的数据通过Flink进行处理,可以使用Flink提供的各种算子进行复杂的数据转换和分析。
3、写入HDFS:处理后的数据通过FileSystemSink实时写入HDFS,在写入之前,可以配置写入路径、文件格式等参数。
实际操作步骤
1、配置Flink环境:确保已经安装并配置了Flink和HDFS。
2、配置连接参数:在Flink的配置文件中配置HDFS的连接参数。
3、创建数据流:使用Flink的DataStream API创建数据流。
4、数据处理:对数据进行清洗、转换和分析等操作。
5、写入HDFS:使用FileSystemSink将数据实时写入HDFS。
注意事项
1、性能优化:在写入大量数据时,需要注意性能优化,包括调整缓冲区大小、并发度等参数。
2、错误处理:在实时写入过程中,可能会遇到各种错误,如网络故障、HDFS存储满等,需要合理设计错误处理机制,保证系统的稳定性。
3、数据一致性:在分布式系统中,数据一致性是一个重要的问题,需要设计合理的容错机制和数据备份策略,保证数据的安全性。
通过Flink实时写入HDFS,可以实现大数据的实时处理和存储,在实际应用中,需要注意性能优化、错误处理和数据一致性等问题,随着技术的不断发展,Flink与HDFS的结合将越来越广泛,为大数据处理领域带来更多的可能性,我们可以期待更多的优化和创新,以应对更复杂的实时数据处理需求。
在12月22日这一天,我们走进Flink与HDFS的世界,体验了实时数据处理的魅力,希望通过本文的介绍,能帮助读者更好地理解Flink实时写入HDFS的原理和操作流程。
转载请注明来自山高海投内控平台,本文标题:《基于Flink实时写入HDFS的数据之旅探索》




 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...